比特币实时交易数据分析
自从 btcc 举办活动以来,比特币的价格浮动巨大, 分析交易数据可能带来巨大的利益。 实时预测下一刻的价格和检测异常的浮动显得很有意义。 下面介绍一下我用 nupic 分析比特币实时交易数据。
交易数据收集与初步处理
我们可以通过 交易 API 快速获取过去24小时内的交易历史
$ curl https://data.btcchina.com/data/trades
[{
"date":"1383286640",
"price":1264.31,
"amount":0.01,
"tid":"680350"
},{
"date":"1383286877",
"price":1264.33,
"amount":1,
"tid":"680351"
},{
"date":"1383286880",
"price":1264.79,
"amount":0.3,
"tid":"680352"
}]很显然这个是每次交易的数据,现在需要合并成每个时间的交易数据,对同一时间的价格取平均值,交易量求和。
var _ = require('lodash');
var data = _.groupBy(return_data_from_api, 'date').map(function(paths) {
var price = _.sum(paths, 'price') / paths.length;
var amount = _.sum(paths, 'amount');
return {
date: paths[0].date,
price: price,
amount: amount
}
});数据仓储
 这里选择是 river-view。
我可以写一个简单的
这里选择是 river-view。
我可以写一个简单的 river 就可以把我咬的数据收集起来并存储,而且有机会被合并到主分支上面。
首先 clone river-view,
然后建立 river btcc-trades
git clone https://github.com/nupic-community/river-view.git
cd river-view
mkdir -p rivers/btcc-trades每个 river 都有两个文件 config.yml 和 parser.js。
交易数据属于 scalar 类型,定义如下:
# file: config.yml
type: scalar时区很重要这里要设对,不然时间都不对了。
# file: config.yml
timezone: Asia/Shanghai数据源:
# file: config.yml
sources:
- https://data.btcchina.com/data/trades最后当然是需要获取的数据了:
# file: config.yml
fields:
- price
- amount下面是 parser.js 的代码:
var _ = require('lodash');
module.exports = function(body, options, temporalDataCallback, metaDataCallback) {
var config = options.config,
fieldNames = config.fields,
metadataNames = config.metadata,
data = JSON.parse(body);
data = _.groupBy(data, 'date');
_.each(data, function(paths, timestamp) {
var metaData = {},
fieldValues = [],
streamId = 'btcc-trades';
_.each(metadataNames, function(propName) {
metaData[propName] = _.map(paths, propName);
});
metaDataCallback(streamId, metaData);
_.each(fieldNames, function(fieldName) {
var value = _.sum(paths, fieldName);
if (fieldName === 'price') {
value = value / paths.length;
}
fieldValues.push(value);
});
temporalDataCallback(streamId, timestamp, fieldValues);
});
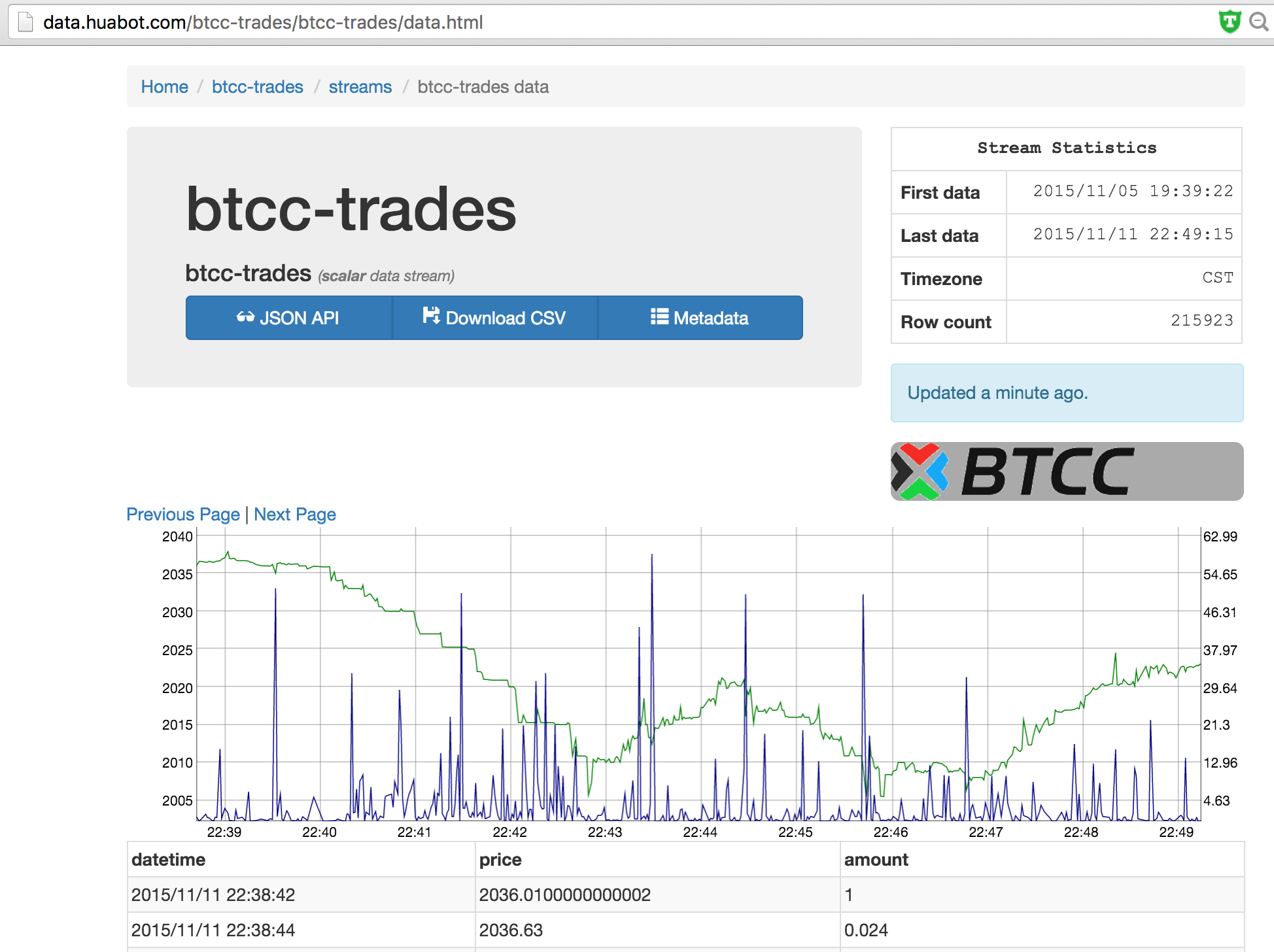
};到这里数据收集和仓储算是完了,代码见: https://github.com/Lupino/river-view/tree/master/rivers/btcc-trades 搜集到的数据见 http://data.huabot.com/btcc-trades/btcc-trades/data.html
数据分析
这里使用 river-runner 进行分析。
首先安装依赖
pip install riverpy
pip install nupicclone 并做初步分析:
git clone https://github.com/nupic-community/river-runner.git
cd river-runner
./run.py -u http://data.huabot.com -r btcc-trades -s btcc-trades -f price这一步会生成 price_out.csv。
river-runner 只会分析最新的 3000 条数据, 所以需要修改一下,让它可以分析所有的数据
diff --git a/run.py b/run.py
index 1dfb805..aa7379f 100755
--- a/run.py
+++ b/run.py
@@ -33,10 +33,10 @@ from nupic.frameworks.opf.modelfactory import ModelFactory
import nupic_anomaly_output
-DEFAULT_RIVER_VIEW_URL = "http://data.numenta.org/"
-DEFAULT_RIVER = "chicago-beach-weather"
-DEFAULT_STREAM = "Oak Street Weather Station"
-DEFAULT_FIELD = "solar_radiation"
+DEFAULT_RIVER_VIEW_URL = "http://data.huabot.com/"
+DEFAULT_RIVER = "btcc-trades"
+DEFAULT_STREAM = "btcc-trades"
+DEFAULT_FIELD = "price"
DEFAULT_PLOT = False
DEFAULT_DATA_LIMIT = 3000
@@ -175,15 +175,11 @@ def getMinMax(data, field):
return (min, max)
-def runModel(model, data, field, plot, logLikelihood):
+def runModel(model, data, field, plot, output):
fieldIndex = data.headers().index(field)
datetimeIndex = data.headers().index(DATETIME_FIELDNAME)
shifter = InferenceShifter()
- if plot:
- output = nupic_anomaly_output.NuPICPlotOutput(field, logLikelihood)
- else:
- output = nupic_anomaly_output.NuPICFileOutput(field, logLikelihood)
for dataPoint in data.data():
dateString = dataPoint[datetimeIndex]
@@ -200,9 +196,6 @@ def runModel(model, data, field, plot, logLikelihood):
anomalyScore = result.inferences["anomalyScore"]
output.write(timestamp, value, prediction, anomalyScore)
- output.close()
-
-
if __name__ == "__main__":
(options, args) = parser.parse_args(sys.argv[1:])
@@ -213,14 +206,27 @@ if __name__ == "__main__":
field = options.field
url = options.url
aggregate = options.aggregate
-
+
if aggregate:
field = 'count'
data = fetchData(url, river, stream, aggregate,
- {'limit': options.dataLimit})
+ {'limit': options.dataLimit, 'since': datetime.datetime(2015, 11, 5)})
(min, max) = getMinMax(data, field)
modelParams = getModelParams(min, max)
model = createModel(modelParams)
- runModel(model, data, field, plot, options.log)
+
+ if plot:
+ output = nupic_anomaly_output.NuPICPlotOutput(field, options.log)
+ else:
+ output = nupic_anomaly_output.NuPICFileOutput(field, options.log)
+
+ while len(data.data()) > 0:
+ since, until = getMinMax(data, DATETIME_FIELDNAME)
+ print("runModel: since=%s, until=%s\n" % (since, until))
+ runModel(model, data, field, plot, output)
+ data = fetchData(url, river, stream, aggregate,
+ {'limit': options.dataLimit, 'since': datetime.datetime.strptime(until, DATE_FORMAT)})
+
+ output.close()数据虚拟化
数据虚拟化使用的是 nupic.visualizations
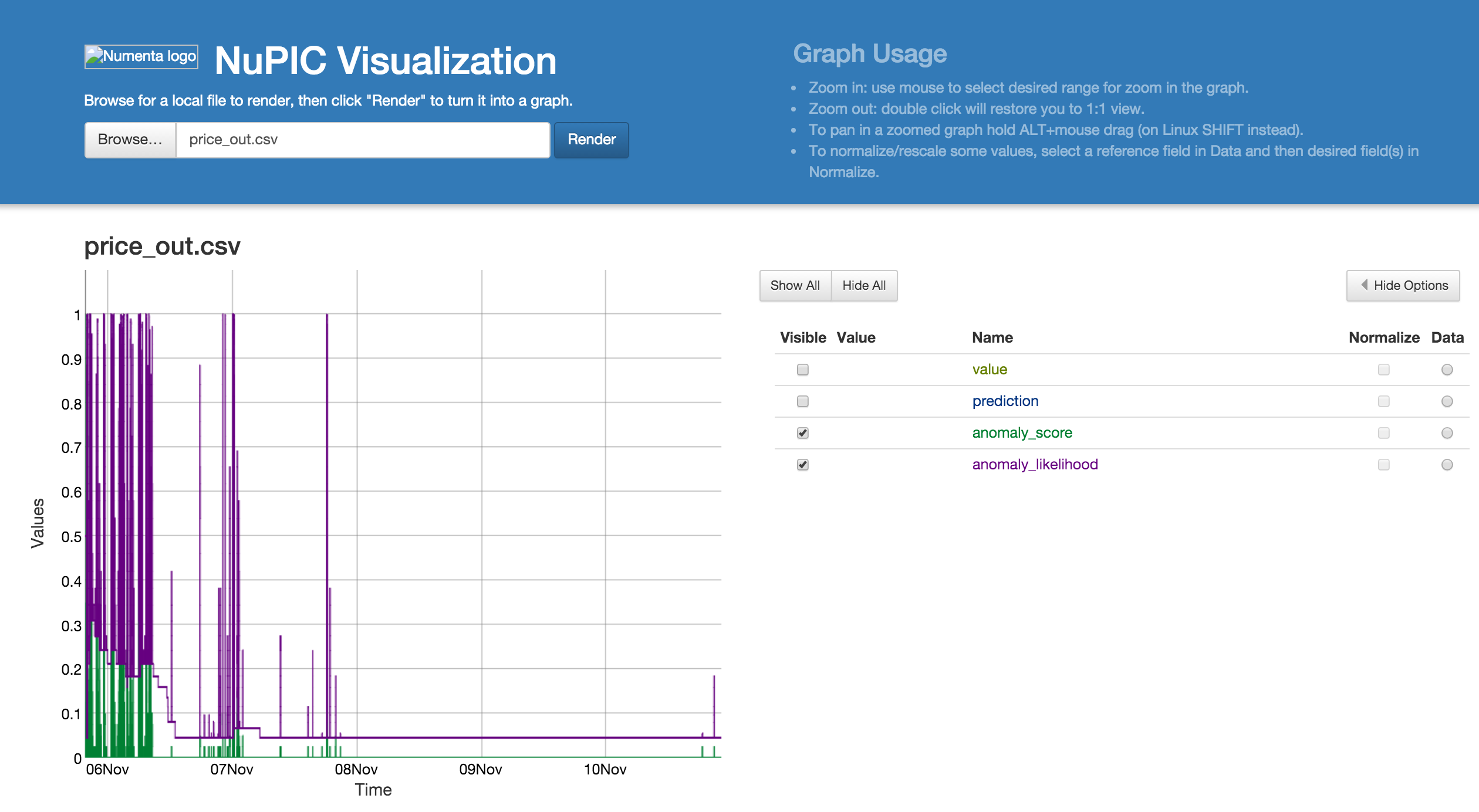
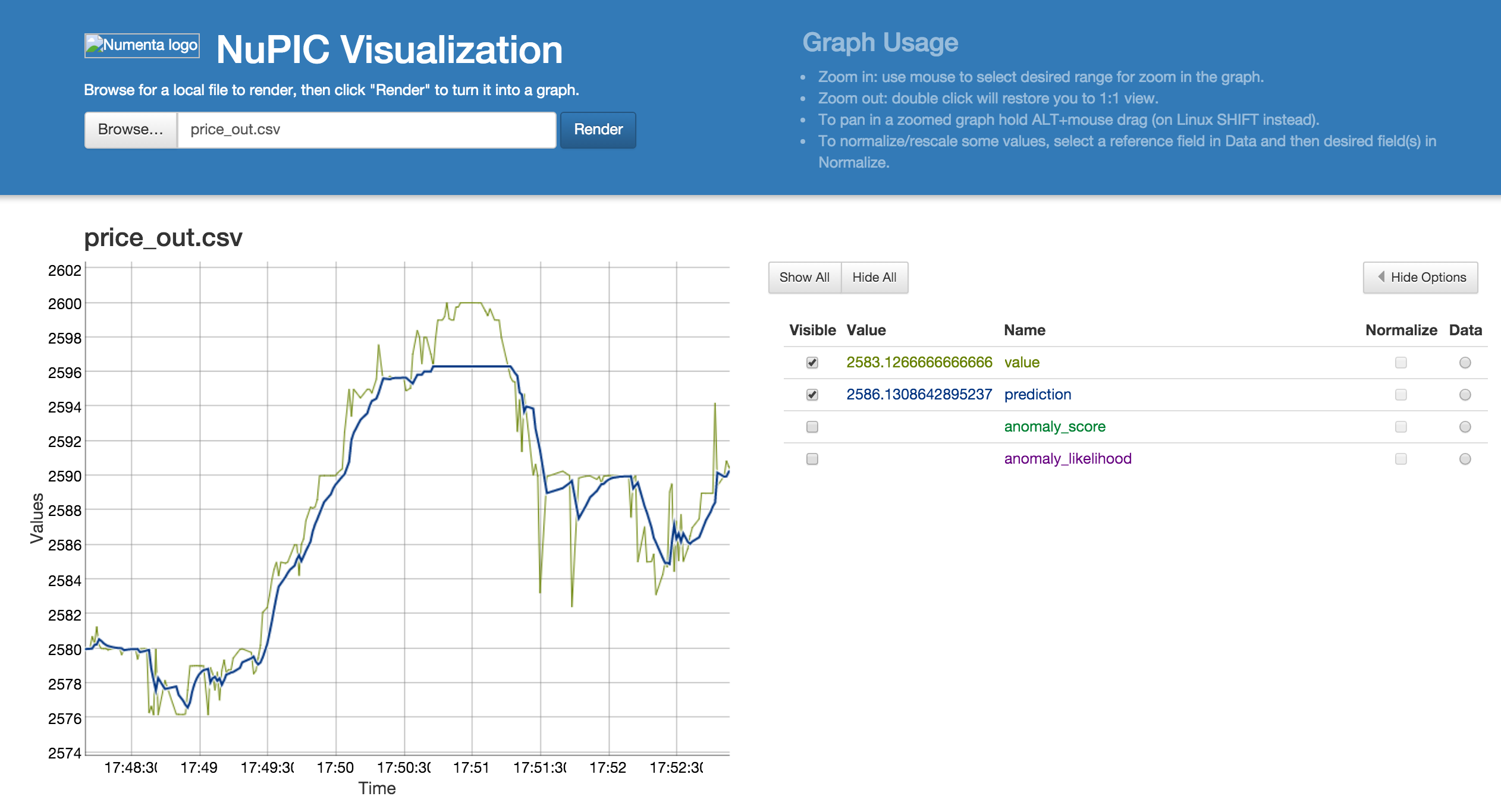
结论
利用 nupic 还是可以相对准确的预测 btc 下一时刻的价格,并且检测出交易的异常。
当然数据分析那一部份还需要进行优化,利用 Swarming 得到最优的网路参数。